Introduction
There are two parts to this assignment. Part one will consist of using Excel and SPSS to conduct regression analysis to see if crime rates (per 100,000 people) are dependent on free school lunches within the same area. A previous study had recently claimed that the free student lunch rate increases the crime rate. This will either be verified or debunked using the SPSS and Excel regression tools. Then, using the regression equation, an estimate will be made for the crime rate of a town if it has a 23.5% free lunch rate. Part two entails using single linear regression, multiple linear regression, and residual analysis to help out the city of Portland see what demographic variables influence 911 calls, and to help out a private construction company by determining an approximate location of where to build a new hospital,
Part 1: Crime and Free Student Lunches
Run the Regression in SPSS
First, it was decided that the percent of free student lunch is the independent variable and that the crime rate is the dependent variable. This is the case because the question at hand is if the free lunch rate influences the crime rate. Not that if the crime rate influences the free student lunch rate.
Then, the regression analysis was ran by navigating to Analyze → Regression → Linear where the free lunch rate was set as the independent variable and the crime rate was set as the dependent variable. This created a couple of nice tables which help explain the relationship between the variables. The first table generated was the Model Summary which is displayed below in figure 6.0. This gives the R value, the r² value, the adjusted r² value, and the standard error of the estimate. The r² value of .173 indicates that there is a very weak relationship between the two variables. The standard error of the estimate looks fairly low at 96.1, but this value doesn't mean anything at the moment. It needs to be compared to other standard error of the estimate values with the same variables but with different values for it to carry meaning.
 |
| Fig 6.0: Model Summary for Free Lunch Rate and Crime Rate |
 |
| Fig 6.1: Coefficients Table |
Using this information provided in the charts, a regression equation was assembled using the y = ax + b format. The equation is Crime Rate Per 100,000 People = 1.685 * Percent Free Student Lunch + 21.819. In the y = ax + b equation, the y represents the dependent variable, the a represents the slope, x represents the independent variable, and b represents the constant.
With this equation, an estimation of crime rate can be calculated with a given free student lunch value. If a town has a free student lunch rate of 23.5%, its estimated crime rate using the regression equation is 61.417 (per 100,000 people).
Using Excel, a scatter plot was created to show the crime rates and free student lunch rates. This can be seen below in figure 6.2. The r² value and the equation of the linear regression line is displayed on the chart as well. The one outlier value which is a crime rate of 704 has significant influence on the regression line. However, outliers do happen, and it would foolish to not include it.
 |
| Fig 6.2: Crime and Free Student Lunch Rate |
Based off of all this information, the study which claimed that the free student lunch rate influences the crime rate can be verified. Using the r² value, 17.3% of the increase in the crime rate can be attributed to the free student lunch rate. The significance level of .005 also indicates that there is a relationship and a correlation between the two. Although this relationship is significant, the free lunch rate doesn't explain very much of the crime rate. Because the significance level is very significant, there is a good amount of confidence in these results.
Part 2: Portland 911 Calls and Future Hospital Location
Introduction
The hypothetical scenario for Part two is that the city of Portland Oregon is concerned about the response time of 911 calls. They want to know what demographic variables may help predict the number of 911 calls. Also, a private company is interested in building a hospital, but they need some help in knowing where to build it. Using single regression, multiple regression, and residual analysis an approximate location for the new hospital will be found.
Methods
Step 1: Run Single Regression in SPSS
The independent variables Jobs, LowEduc, and FornBorn were chosen to run single regression analysis against the dependent variable Calls. Jobs represents the number of jobs in the census tract, LowEduc is the number of people without a high school diploma, FornBorn is the number of foreign born residents, and Calls is the number of 911 calls. The output of this analysis will show how well the independent variable is able is to predict and explain the number of 911 calls.
Step 2: Run Multiple Regression in SPSS and Apply the Kitchen Sink Approach
Then, using the independent variables Jobs, Renters, LowEduc, AlcoholX, Unemployed, FornBorn, Med Income, and CollGrads, a multiple regression analysis was ran using calls as the dependent variable. Med Income is household median income, and CollGrads is the number of college graduates. The option to include collinearity diagnostics was checked before running the analysis. This can be found by navigating to Analyze → Regression → Linear → Statistics.
The kitchen sink approach is used to help see which independent variables are driving the linear regression equation the most. To start, one looks at the significance and Beta values of the independent variables found in the output of the analysis. One then throws out one variable at time based on the significance and Beta values. Generally, the variable which has the lowest Beta value which isn't significant is thrown out. The multiple regression is run again with all of the variables except the one tossed out. Again, another independent variable is chosen to be tossed based on the Beta and significance levels. This process continues until all of the variables ran in the multiple regression analysis are significant. There were three independent variables which were found to driving the regression equation the most using this method: Jobs, LowEduc, and Renters.
Step 3: Use the Stepwise Apprach with Multiple Regression
The stepwise approach is similar to the kitchen sink approach in that it finds the variables which drive the linear regression equation the most, but instead of manually weeding out the variables like in the kitchen sink approach, the computer automatically chooses the variables it thinks drive the equation the most. The stepwise approach is simple. It shows the user the variables which area included and excluded and all of the stats for both of them. It is a much easier method to use than the kitchen sink approach. Running the multiple regression analysis using the stepwise method, the computer chose Renters, LowEduc, and Jobs as the three variables which drive the linear regression equation the most.
Step 4: Find the Residuals of the Included Stepwise Varibales and Most Important Single Regression Variable
The residuals of the stepwise output were of three variables Renters, LowEduc, and Jobs together. They were calculated by running the stepwise multiple regression analysis again. This time though, the box to have standardized residuals calculated had to be checked before running the regression. This can be found by navigating to Analyze → Regression → Linear → Save and then checking the Standardized check box in the Residuals section. This created a new field containing the residuals for for each census tract. The field was renamed as ResidualsStep. Then, a new Excel workbook was created to help standardize the data so that only the UniqID and ResidualsStep fields where in the document.
The most important single linear regression variable of LowEduc, Jobs, and ForgnBorn was LowEduc. This was determined because of these three variables, LowEduc had the highest significant r² value. The residuals were then calculated using the same methods as with the stepwise variables. This residual field was renamed as LowEduResid and was copied and inserted in the same Excel spreadsheet used for the stepwise residuals.
Create Maps
Lastly, 4 maps were created. The first map was of just the number of 911 calls by census tract. The second map was of the residuals of the LowEduc variabe. The third map was of the residuals of the three included variables in the stepwise output. Lastly, the fourth map was created to show the prime census tracts for which the hospital should be built in
Results / Discussion
Single Variable RegressionForeign Born
Below in figure 6.0 is the Model Summary of the linear regression output of having calls as the dependent variable and ForgnBorn as the independent variable. It shows that the r² value is .552 which indicates that there is a fairly strong relationship between foreign born individuals and the number of 911 calls. It also means that the number of foreign born citizens in a census tract can help expain 55.2% of the variation in the number of 911 calls.
 |
| Fig 6.0: ForgnBorn Regression Output |
 |
| Fig 6.1: ForgnBorn Coefficents |
Jobs
The Model Summary for the linear regression output between the number of jobs and the number of 911 calls is shown below in figure 6.2. The r² value for this relationship is only .340 which means that there is a moderate correlation between the two variables and that 34.0% of the variation in the increase of the number of 911 calls is because of the number of jobs.
 |
| Fig 6.2: Jobs Model Summary |
The Coefficients part of the output for this regression is shown below in figure 6.3. The significance value of .000 means that the null hypothesis is rejected and that there is a relationship between the number of jobs and the number of 911 calls. The B value of .007 means that there is a positive relationship between the two as well. The linear regression equation for this output is The Number of 911 Calls = .077 * The Number of Jobs + 18.640. This equation tells the reader two things. The first is that each time there is an added job in the census tract, the number of 911 calls increases by .077 calls. The second thing if there were no jobs in the census tract, theoretically there would be 18.640 911 calls.
 |
| Fig 6.3: Jobs Coefficients |
Low Education
The last variable used to run linear regression against the number of 911 calls was the number of people without a high school degree (LowEduc). The Model Summary for this analysis is shown below in figure 6.4. The r² value of .567 indicates that there is a strong relationship between Calls and LowEduc and that 56.7% of the increase in the number of calls can be attributed to the number of people without a high school degree.
 |
| Fig 6.4: LowEduc Model Summary |
The Coefficients section of the output is shown below in figure 6.5. The significance value of .000 means that there is a relationship between LowEduc and Calls, and that the null hypothesis is rejected. Using the B values, the linear regression equation can be put together. It is The Number of 911 Calls = .166 * The Number of People Without a High School Degree + 3.931. This equation tells the reader that for each time there is added person without a high school degree in the census tract, the number of 911 calls increases by .166 calls, and that if there were no persons in the census tract without a high school degree, then there would be 3.931 911 calls.
 |
| Fig 6.5: LowEduc Coefficients |
Although these three outputs demonstrates that there are relationships between the number of 911 calls and the number of foreign born citizens, the number of jobs, and the number of people without a high school degree individually, it doesn't help out the hypothetical company in determining where to put the new hospital by itself.
Multiple Variable Regression
 |
| Fig 6.6: Multiple Regression Model Summary |
Next, the Coefficients table for the multiple regression output is shown below in figure 6.7. This shows which variables have a significant relationship with the number of 911 calls. These significant variables include Jobs and LowEduc. With all the variables together, all the other variables besides these two are not pegged as significant by SPSS. This means that for all the variables except Jobs and LowEduc, the null hypothesis is failed to be rejected meaning that statistically there is no relationship between those variables and the number of 911 calls. However, a linear regression equation can still be generated using the B column. The Equation is The Number of 911 Calls = The Number of Jobs * .005 + The Number of Renters * .019 + The Number of Persons Without a High School Degree * .136 + The Number of Alcohol Sales * -.00001597 + The Number of Unemployed Person * -.01 + The Number of Foreign Born Persons * -.014 + The Average Household Median Income * -.00007827 + The Number of College Graduates * .030 + 2.526. The variables Jobs, Renters, Low Educ, and CollGrads have a positive relationship with the number of 911 calls, and the variables AlcoholX, Unemployed, ForgnBorn, and MedIncome have a negative relationship with the number of 911 calls.
 |
| Fig 6.7: Multiple Regression Coefficients |
Some collinearity diagnostics statistics were also generated while running the multiple variable regression. This can be seen below in figure 6.8. This table can be used to see if multicollinearity is present. Multicollinearity is when the independent variables correlate too much with each other, thus causing there to be issues with the multiple regression correlation. To check for this, one first looks at the Eigen value in the last dimension of the chart. The closer this value is to 0, the more likely multicollinearity present. The Eigen value in this regression is .014 which is fairly close to 0. If Eigen value is not close to 0, then it is likely that multicollinearity isn't present. If it looks like it may be present, then one looks at the condition index. If the condition index is above 30, then multicollinearity is present. If it's below 30, then no multicollinearity is present. The condition index for this regression output is 21.769, which indicates that the is no multicollinearity between the independent variables. If this index value were to be greater than 30, then one would have to look at the variance proportions of the variables. The independent variable which has a variance proportion value closest to 1 would be thrown out and then a new multiple regression output would be created with out it in an attempt to eliminate multicollinearity.
 |
| Fig 6.8: Collinearity Statistics for the Multiple Regression Output |
The multiple regression output doesn't do much in the way of helping out the hypothetical company place the hospital either by its self. It does help to see how well certain variable relate with the number of 911 calls though.
Kitchen Sink Output
Below in figures 6.9 and 6.10 are the Model Summary and the Coefficients output of the kitchen sink method executed in step 3 of the methods section. The r² value is .771 which indicates that there is a strong relationship between Jobs, LowEduc, and Renters. This is because the weaker variables were weeded out in the process of getting to this point. |
| Fig 6.9: Kitchen Sink Model Summary |
 |
| Fig 6.10: Kitchen Sink Coefficients |
The same three variables were selected from executing the stepwise output. This can be seen below in figure 6.11 in the Model Summary. The computer liked the variables Renters, LowEduc, and Jobs. The .711 r² value for these variables are found in the bottom row of the chart. The first two r² values are not of all three variables put together. The first one is just of Renters, and the second one is of Renters and LowEduc. The last row is of all the variables together. This r² value shows that there is a strong relationship between the independent variables and the number of 911 calls. Not surprisingly, the same variables that were selected to be important using the kitchen sink approach were also selected by the computer in the stepwise output approach.
 |
| Fig 6.11: Stepwise Model Summary |
Next, figure 6.12 shows which variables were not included in the stepwise output. These can be found in the bottom third of the chart. These variables are AlcoholX, Unemployed, ForgnBorn, MedIncome, and CollGrads. The three sections of the table show the computers thought process. The computer picked one variable it though was important each time. Then compared the rest of the variables to each other again and then picked out another variable it thought was important. This process was done one more time until all the the variables it thought were important were selected.
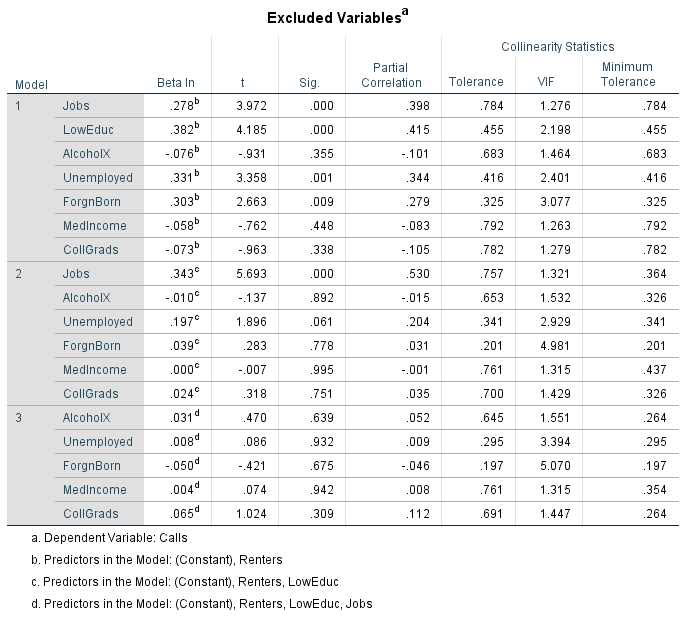 |
| Fig 6.12: Excluded Variables |
The Coefficients table for the stepwise output is displayed below in figure 6.13. Again, the most important part of this table is found in section 3 where all three variables are placed together. Notice that all of the significance levels are under .05. This means that the null hypothesis is rejected and that there is a relationship between the independent variables Renters, LowEduc, and Jobs with the number of 911 calls. Using the B values, the regression equation The Number of 911 Calls = Renters * .024 + LowEduc * .103 + Jobs * .004 + .789 can be assembled. Because LowEduc has the highest beta value, it drives the equation the most.
 |
| Fig 6.13: Stepwise Coefficients |
Maps
This first map shown below in figure 6.15 shows the number of 911 per census tract. The number of 911 calls don't need to be standardized to population because each census tract approximately populates the same number of people. There is a good amount of clustering in the number of 911 calls. There are five counties located in the northern part of the census tracts in the map which have between 57 and 176 911 calls. They are located near the suburb of Beaverton which can be seen somewhat through the map.
 |
| Fig 6.15: Number of 911 Calls Map |
This next map shown below in figure 6.16 shows the standard deviations of the residuals for the LowEduc variable. This map shows how well the equation 911 Calls = .166 * The Number of People Without a High School Degree + 3.931 predicts the number of 911 calls. The darker the red or blue, the worse the equation did at predicting the number of 911 calls. The more yellow the census tract is, the better the job the equation did at predicting the number of 911 calls for that census tract. Census tracts in red are where there is a higher standard deviation of the residuals. This means that the 911 calls regression equation under predicted the number of 911 calls in these areas. The census tracts in blue are where there are lower standard deviation of the residuals. This means that the 911 calls regression equation over predicted the number of 911 calls in these areas.
Some of the census tracts which are red overlap the areas where there are a higher number of 911 calls. There are two census tracts which stand out. They are the ones which have very high residuals from the regression equation. These two counties overlap with the two of the counties which have at least 57 911 calls from the cloropleth map above in figure 6.15.
 |
| Fig 6.16: Low Education Residual Map |
This next map displayed below in figure 6.17 shows the residuals by census tract of the variables Renters, LowEduc, and Jobs. The same analysis can be applied here. The red census tracts are where the equation / model The Number of 911 Calls = Renters * .024 + LowEduc * .103 + Jobs * .004 + .789 under predicted the number of 911 calls. The blue census tracts represent the tracts which the model over predicts the number of 911 calls.
 |
| Fig: 6.16: Renters, Low Education and Jobs Residual Map |
 |
| Fig 6.17: Best Census Tracts For a Hospital |
As far as for the city of Portland, These independent variables Renters, Low Education, and Jobs do the best at explaining where 911 calls come from.
Conclusion
In conclusion, the prime census tracts for a new hospital were found by using US census demographic data and by analyzing it using SPSS and ArcGIS software. This proves that demographic data can be used to help solve real world issues. Thinking about other applications which could use this type of analysis, although the data in this assignment only looked at placing a new hospital, GIS firms or local governments could use identify areas of where to place a new school, gas station, store, assisted living center, and many other things.Although not all of the SPSS output data was used in the maps, It is possible that one could use many more combinations of independent variables to achieve any desired output. It it good practice to start by looking at some variables, just like in this assignment, and then see which variables explain the dependent variables the best. Both the kitchen sink and stepwise approach were used in this lab. However, the kitchen sink approach was used to gain a better understanding of how filtering independent variables works. In future similar analysis, a stepwise regression output would suffice.
No comments:
Post a Comment